
In October last year, I began my ongoing critique of the face nappy phenomenon by tearing into the truly atrocious Bangladesh Mask Study.
You can read the article here if you haven't already done so, but to quickly recap:
The study, hailed by the mainstream media as definitive proof that masks were effective in preventing COVID, was conducted in rural Bangladesh. It allegedly involved 600 villages and 342,126 adult participants. Among this sample, the proportion of individuals who developed "COVID-like symptoms" was 7.62% (N = 13,273) in the mask group and 8.62% (N = 13,893) in the control group. That's a pathetic absolute difference of 1%.
COVID-19 symptoms are not only identical to those of regular cold, flu and pneumonia but also overlap with numerous other health conditions. Therefore, "COVID-like symptoms" is a rather nebulous and useless category from which to judge the anti-COVID efficacy of masks.
The real question is, how many participants in each group actually became infected with COVID-19 during the study?
Well, of the 27,166 participants reporting "COVID-like symptoms," only 10,952 (40%) consented to having blood samples taken. Of the collected blood samples, 9,977 were actually tested for Sars-Cov-2 antibodies (seroprevalence). From this truncated sample, COVID seroprevalence among the mask group was 0.68% compared to 0.76% in the control group - a piddling absolute difference of 0.08%.
These figures show no benefit for masks, and also show that, when subject to blood testing as opposed to the farce that is PCR, most people displaying "COVID-like symptoms" do not in fact have COVID-19.
The study, in other words, failed to show any benefit for donning facial underwear.
It also confirmed that the whole COVID charade is a monumentally overblown wank. When you have such a small number of people testing positive for a disease with a 99.85% survival rate, it really is time to fess up and admit the COVID-19 scare campaign has been a massive psy-op.
Not only was the data a bust in terms of supporting mask use, but the methodology employed by the oligarch-funded researchers was truly appalling. The randomization strategy left much to be desired; it did not involve randomly assigning the intervention (masks) to individuals within the same village, as you would reasonably expect. Nope - entire villages were assigned to be either mask or no-mask locations, which added a huge extra confounder to the study. The study was relying on the assumption that Bangladeshi villages are all carbon copies of one another, an unlikely proposition given that towns close to each other routinely exhibit distinct characteristics. The randomization was not in fact true randomization, but involved a manual selection process: The researchers stratified villages based on geographic location and available case data, and then selected one treatment and one control village from each pair.
You'll note above that I've italicized "available case data": The shrill Twitter protestations of Lyman Stone-types notwithstanding, it is clear the researchers had a very incomplete picture of baseline infection levels at the start of the study. Given the impact of previous infection upon subsequent immunity and reinfection, this was a huge potential flaw. As El Gato Malo so rightly points out, excuses like "we did the best we could under the circumstances" or "it's a poor country, what do you expect?" simply don't cut it when you are performing what is supposed to be controlled scientific experimentation.
This type of study is known as a cluster randomized controlled trial, in which groups of subjects (as opposed to individual subjects) are randomized. These types of studies are often hyped as extra-informative because of their large size, but bigger is not necessarily better. A cluster randomized trial makes sense when examining the effect of, say, water purification on community health. In the case of an intervention such as masks which - all soppy "we're in this together" propaganda aside - are worn by individuals, then the cluster design becomes a dubious choice. In the Bangladesh Mask Study, for example, what was really (semi)randomized and studied was not 340,000+ individuals, but 600 Bangladeshi villages.
As I explained in my previous article, the trial was badly managed, compliance was far from optimal, and the researchers went on an endpoint binge, cramming an absurd number of sub-interventions into what was an already poorly controlled trial.
The researchers themselves were funded by 'non-profit' outfits GiveWell.org and Innovations for Poverty Action, who in turn receive funding from what reads like a who's who of globalist technocrat outfits: These include the likes of George Soros' Open Society Foundations, the Bill & Melinda Gates Foundation, the heavily-left Omidyar Network, the Ford Foundation, and a host of United Nations agencies.
Of course, rather than admitting the study was a poorly-conducted mess that showed no benefit for masks, the heavily-biased authors audaciously claimed the Bangladesh balls-up in fact demonstrated the efficacy of masks. They shamelessly ignored the miniscule and clinically insignificant absolute differences, and instead hyped the relative risk differences - which were still pathetic at 9.3% for masks overall and 11.2% for those assigned to wear surgical masks.
As I noted in my previous article, relative risk reductions for seroprevalence of 9.3% and 11.2% would be cause for a big yawn in a tightly controlled, blinded trial. In a non-blinded, semi-randomized shitshow like the Bangladesh study, they are an absolute joke.
Others have similarly lambasted the terrible Bangladesh study. El Gato Malo, Steve Kirsh and UC Berkeley professor Ben Recht have posted especially compelling dissections of the trial.
Kirsch and Recht took the data posted by the study authors here, and after running numerous analyses, further highlighted the misleading manner in which the study has been reported. One especially illuminating finding, which would be funny were it not a reflection of just how far science has fallen, is that purple cloth masks showed no advantage over going maskless, but red cloth masks did. Red cloth masks, in fact, showed higher 'efficacy' than surgical masks.
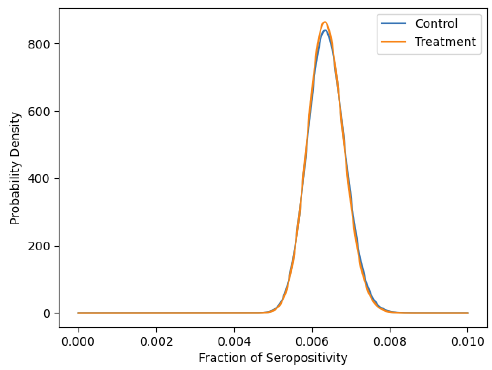
Purple masks versus no masks.
So we're supposed to believe that changing the color of a mask from purple to red suddenly increases its ability to prevent COVID-19 transmission. Obviously, such a claim is absurd.
Despite their seeming fetish for sub-analyses, the authors never included the above graph in their 2021 or 2022 papers.
Funny that.
Science Sucks. The Journal, That Is.
Science, a.k.a Science Magazine, is a peer-reviewed journal of the American Association for the Advancement of Science (AAAS). First published in 1880, the journal is one of the most widely read in the world. As Wikipedia notes, "Competition to publish in Science is very intense, as an article published in such a highly cited journal can lead to attention and career advancement for the authors. Fewer than 7% of articles submitted are accepted for publication."
So you might assume any research finding its way onto the pages of Science must be of the very highest quality.
You'd be sorely mistaken. Science, like a lot of journals nowadays, seems largely indifferent to quality research and far more concerned with pimping politically correct causes like climate change and COVID hysteria.
Which explains why the junk-grade Bangladesh Mask Study recently passed Science's 'peer review' process and featured in its 2 Dec 2021 issue.
That's right, dear readers: One of the most widely-read science publications in the world has seen fit to validate this garbage study by publishing it. We're talking a study with demonstrably deficient methodology, and the subject of widespread criticism that no-one has been able to refute (some guy called Lyman Stone tried, and even called El Gato Malo a liar in the process. As someone who knows what it's like to be called a liar by defenders of lies, I'd be lying myself if I said I didn't find Gato's subsequent cyber-goring of Stone most gratifying).
Despite its incredibly poor quality, and the untenable conclusions drawn from the Bangladesh Mask Study, it was allowed to sail through Science's peer review process. Most of the big lies appearing in the original study report have been repeated in the Science paper.
There have been some changes in the numbers, though, and they don't exactly inspire confidence in the rigor of the study's conduct: The original 342,126 adult participants have become 342,183 adults. The 13,273 mask participants allegedly reporting "COVID-like symptoms" has been culled to 12,784, while the control group has undergone a smaller reduction (previously 13,893, now 13,287). Which leaves a pathetic absolute difference between groups of 0.97% - less than a single percent.
Woohoo.
In their original preprint report, the authors claimed 10,952 of those reporting "COVID-like symptoms" consented to having blood samples taken. In the Science article, that number has been reduced to 10,790. In the original paper, we were told 9,977 of these blood samples were tested; in the appendix of the Science paper this has again inexplicably shrunk to 9,512 samples. One wonders what happened to the other people and tested samples, but the percentages are ultimately the same: As in the original paper, COVID seroprevalence among those consenting to blood tests was still 0.68% in the mask group and 0.76% in the control group.
Despite the piddling difference, Science clearly had no issue with the researchers claiming "We find that surgical masks are particularly effective in reducing symptomatic seroprevalence of SARS-CoV-2."
Yep, when you have an agenda to push, a 0.08% difference in a trial where the highly deficient methodology could have swayed the results by a far greater degree suddenly becomes proof that a measure is "particularly effective."
Give me a break.
One glaring omission in both the original preprint and the Science paper is the lack of actual number of participants who experienced the seropositivity endpoint. Readers are subjected to a barrage of percentages and intervention coefficients, but I just wanted to know how many damn people in the mask and control groups tested positive for Sars-Cov-2. I scoured through the preprint, the Science paper, and the supplementary material to the Science paper, but the numbers were nowhere to be seen.
The researchers posted their raw data here, so I downloaded it and found a file called "endline_blood_results." Bingo, I said to myself - until I attempted to open the file and saw that it had a .dta extension. Oh joy.
Thankfully, Recht - an electrical engineer and computer scientist - has already accessed the raw data. Apparently it still didn't contain the raw numbers I was seeking, but he was able to compute them from the provided data: He found there were 1,106 symptomatic individuals confirmed seropositive in the control group and 1,086 such individuals in the treatment group.
Let those figures sink in for a moment: A difference of only 20 cases in a study of over 340,000 individuals over a period of 8 weeks!
Little wonder the authors were so reluctant to simply present the actual seroprevalence numbers in a straightforward, transparent fashion - they hardly support the contention that "surgical masks are particularly effective in reducing symptomatic seroprevalence of SARS-CoV-2"!
Despite the importance of these numbers, the so-called peer-reviewers at Science clearly had no problem with their complete absence from the paper and supplementary material. The primary endpoint of the study was whether masks reduced the number of individuals reporting "COVID-like symptoms" and testing seropositive for Sars-Cov-2 during the trial - yet at no point are we told just how many people tested positive for Sars-Cov-2.
So How Do They Get Away With This Shambolic Carry On?
They get away with it because modern health and medical science is obsessed with statistical significance. The reason these highly corrupted sectors love statistical significance is because, with a little sleight of hand, it allows them to repackage disappointing non-supportive results as supportive.
Before I proceed further, it bears reiterating the differences between clinical significance and statistical significance. If, in a large and tightly controlled trial, a treatment slashes the absolute incidence of a negative health outcome by half, then that is clinically significant. Any sane clinician should be delighted by the possibility of slashing the risk of a disease in half by implementing a single intervention.
On the flipside, if that same trial only detects a 1% absolute difference, then the clinical significance is pretty much non-existent, because you would likely need to treat thousands of people to save a single person from experiencing the negative health outcome. That's assuming the 1% difference is real and not merely a result of chance.
However, if the trial population is large enough, your unimpressive 1% reduction can not only be reframed as a 11% relative risk reduction (click here for an explanation of how the relative risk scam works), but may also still be of statistical significance. In other words, your statistics software package may conclude that the result, as clinically insignificant as it may be, has a low probability of being due to chance. It's a piddling difference but, hey, at least it's probably a genuine piddling difference.
The statistical significance game allows researchers to hype weak and clinically insignificant findings as "significant." They conveniently omit the words "clinically" and "statistically", and simply tell you the results are "significant." This behaviour is not rare but routine and happens on a daily basis in the terribly corrupted world of science.
It's exactly what happened in the Bangladesh Mask Study. As Recht notes, "We don’t need a p-value (probability value) to tell us 10% efficacy is not helpful in this context." Only an idiot would fail to see that a piddling difference of 20 people between groups in a study of over 300,000 people is the very definition of insignificant.
But, to prove a point, he proceeds to calculate the statistical significance anyway. If you want to get your math geek on and see exactly how he computed the p-values, his post can be found here. What I can relay here is that after factoring in the statistical limitations of cluster trials, he found none of the multiple hypotheses tested by the Bangladeshi authors achieved a p-value of less than 0.5 (a widely accepted cut-off value for statistical significance).
Using the seropositivity relative risk reduction and (control group) prevalence figures cited by the Bangladesh study authors, Recht also calculated how many participants the trial would have needed in order to reliably achieve statistically significant results.
The answer was 1.1 million people, over 3 times larger than the actual study size!
As Recht writes:
"When a power calculation reveals a trial needs more than a million subjects, researchers need to pause to think if they are asking the right question. It is likely impossible to conduct a precise experiment that rules out all confounding at such a scale ... And if one really expects the clinical significance to be this small, why invest all of these resources into running an RCT instead of looking for more powerful interventions?"
Masks don't work, a fact that should be glaringly obvious when you need to manipulate the living daylights out of your non-supportive data. Shame on Science for giving this truly atrocious study the misleading aura of scientific respectability.
The fall of Science ... and science
It is both sad and fitting that a publication called Science adheres to such appalling standards of rigor. It mirrors the wider field of science, which continues to experience a marked and accelerating decline in quality. Randomized clinical trials, once the gold standard of clinical research, have largely deteriorated into corrupted shams that are ruthlessly distorted into supporting dubious political, financial and ideological agendas.
In my next article, I'll share with you another story that shows just how abysmal the alleged 'peer review' process at Science is. It involves an email exchange I had a few years back with a prominent proponent of the absurd Anthropogenic Climate Change theory. During the exchange, this arrogant individual unwittingly let slip with a staggering revelation, one that further underscores the poor standards adhered to both by Science and the world's climate change scaremongers.
Ciao,
Anthony.
Note: Recht et al have also posted a preprint titled "A note on sampling biases in the Bangladesh mask trial," available here.
If You Found This Article Helpful, Please Consider Leaving a Tip
This site is self-funded and relies on reader generosity. Researching and writing articles like this takes a lot of time, so any and all tips are greatly appreciated!